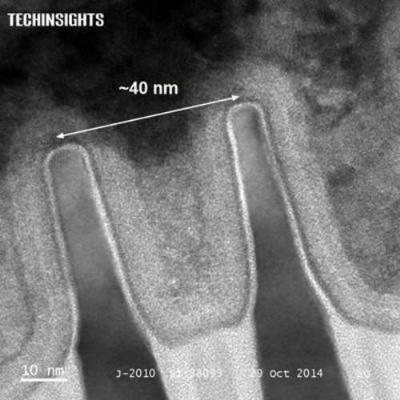
The term "node" is used by the semiconductor industry to characterize major targets in their manufacturing roadmap. See here for more information that you could ever possibly want about this. The phrase "xx nm node" means that the smallest spacing between repeated features on a chip along one direction is xx nm. It does not actually mean that transistors are now xx nm by xx nm. Right now, the absolute state of the art on the market from Intel are chips at the 14 nm node. A cross-section of those taken by transmission electron microscope is shown to the right (image from TechInsights), and Intel has a nice video explaining the scheme here. The transistors involve fin-shaped pieces of silicon - each fin is about 14 nm wide, 60-70 nm tall, and a hundred or more nm long. One transistor unit in this design contains two fins each about 40 nm apart, as you can see in the image. The gate electrode that cuts across the fins is actually about 40-50 nm in width. I know this is tough to visualize - here is a 3-fin version, annotated from a still from Intel's video. In these devices current flows along the long direction of the fin, and the gate can either let the current pass or not, depending on the voltage applied - that's how these things function as switches.

So: The 7 nm node IBM chip is very impressive. However, don't buy into the press release wholesale just yet - there is a lot of ground to cover before it becomes clear that these chips are really "manufacturable" in the sense commonly used by the semiconductor industry.
I'll touch on two points here. First, yield. The standard architecture of high performance logic chips these days assumes that all the transistors work, and we are talking about chips that would contain several billion transistors each. In terms of manufacturing and reliability, integrated semiconductor devices are freaking amazing and put mechanical devices to shame - billions of components connected in a complicated way, and barring disaster these things can all work for many years at a time without failure. To be "manufacturable", chip makers need to have the yield of good chips (chips where all the components actually work) be high enough to cover the manufacturing costs at a reasonable price point. That typically means yield rates over at least 30%. Back in the '90s Intel was giving its employees keychains made from dead Pentium processors. It's not at all clear that IBM can really make these chips with good yields. Note that Intel recently delayed manufacturing of 10 nm node chips because of problems.
Second, patterning technology. All chips in recent years (including Intel's 14 nm and even their prototype 10 nm node products) are patterned using photolithography, based on a light source with a wavelength of 193 nm (!). Manufacturers have relied on several bits of extreme cleverness to pattern features down to 1/20 of the free-space wavelength of the light, including immersion lithography, optical phase control, exotic photochemistry, and multiple patterning. However, those can only carry you so far. IBM and their partners have decided that now is finally the time to switch to a new light source, 13.5 nm wavelength, the so-called extreme ultraviolet. This has been in the planning stages for years, with prototype EUV 300 mm wafer systems at Albany Nanofab and IMEC for about a decade. However, changing to new wavelengths and therefore new processing chemistry and procedures is fraught with challenges. I'm sure that IBM will get there, as will their competitors eventually, but it wouldn't shock me if we don't see actual manufacturing of 7 nm node chips for four or five more years at least.
7 comments:
Nice explanation! I always wondered exactly how this node translated into real dimensions. So it's the width of the channel (and the length is, now, 5-6 times larger).
7 nm wide means about 25 atoms wide. I wonder how they can get the impurity (dopant) statistics good enough for reproducible behavior between different statistics. Do they still use heavily (e.g. p++) doped source and drains? If one atom moves into the channel this could quite dramatically alter its properties. (See e.g. the Bohr radius of a P atom in Si and compare to 7 nm...).
Question:
What does this 30% yield mean? I'd like to know how reliable they can produce transistors. Do 1/3 of the transistors fail?
The link you give mentions a 30% yield of a *chip*. But a chip contains *many* transistors. Is a chip rejected when one transistor is bad? Or ...
(But this may be proprietary knowledge...?)
Nice post, Doug! I was the Micron assignee to SUNY Albany Nanotechnology Institute working on EUV. It's an amazing technology, but had a lot of problems. I hope there has been great progress since I was involved, but my take on the whole thing was that the cost of ownership would be too high in the near future for adoption. I can go into the specific difficulties if anyone is interested.
To answer the last question first, let me take the perspective of a DRAM or NAND Flash manufacturer. I can't really speak about devices that are logic-intensive, but I'd imagine the answer is the same. A single wafer will have many replicants of a the device on it, and these are referred to as die (as in 'the die is cast'). Depending on the device and the specifics of the wafer, you may have around a ballpark of 150 devices on a wafer. As I said, though, this depends strongly on the device, so consider this an order of magnitude figure. Yield is usually discussed in terms of properly functioning die, so for example, if you have 150 die, at 30% yield, you have about 50 properly functioning devices on your wafer. This is of course, a terrible yield, but it's good enough to show that you're on to something, and it's considered 'just' an engineering challenge to bring the yield up. When a die fails, it means that there are enough 'mistakes' on it to prevent it from working properly. The reasons it fails are legion and can be anything from deformities in the lithography due to the spin-on process, wafer topology, inhomogeneities in the etch process or dopant implantation, phase of the moon, color of your socks, etc. A 30% yield usually means that for standard commoditization, the wafer costs more money than it can make by selling its die. You want yields in the 90's, preferably 99.999... Each device, at least in DRAM, has built-in redundancy. This means that a certain number of elements in the array can fail and you'll still have a yielding die. What cannot fail is the periphery devices that access and control the array elements, because failure here takes out many array elements, not just a few, and these cannot be made redundant.
I'm a little out of touch to give a good current answer to the first question. As far as I know, yes, p++ is still used. The purity control on the incoming materials and processes is incredible, and you may be surprised that it's even possible to achieve this level. A single impurity atom can alter the properties significantly, but there are ways to make the devices tolerant of this, to an extent. In the CMOS image sensor industry, we could see the effects of a single tungsten atom impurity, which may or may not cause the device to fail. In the event of a failure, we could write into the NVM control to not use that pixel, and simply interpolate it's value from neighboring pixels. Obviously, there are severe limits to what density of fails you can get away with.
In terms of the lithography- and this is a huge rabbit hole one can base a career on- there are all kinds of tricks get the smallest reliable devices without having to go to a shorter wavelength. Immersion litho is one of these. In general, these fall under the rubric of 'reticle enhancement techniques'. This involves changing the spatial coherence of the illumination source, phase shifts on the reticle, pitch multiplication (which is a very clever thing!), tuning the litho aperture, and a handful of other hacks.
Thanks, Unknown - very helpful answers!
Anon, Unknown covered this better than I could. Picture a 300 mm wafer covered with would-be processors (say 150 dies). When I said 30% yield, I meant 30% of those 150 have to test out as working properly. I overstated the issue by implying that there was no redundancy, but in general the success rate on individual transistor components has to be many-9s - very very high. At least historically, die yields of around 50% in high performance processors were not show-stoppers at the beginning of real sales. That yield number depends a bit on how "failure" is defined. For example, you could have chips that would work acceptably at lower clock speeds than the design point, but would fail at the designed clockspeed. Once upon a time, these failures (or rather, other members of such a batch) were relabeled and sold to operate at lower speeds, spawning the whole sport of "overclocking".
Unknown, regarding the doping, I don't really know details. My impression (possibly erroneous) is that at least some finFET designs are for fully depleted channels. here (pdf!) is a detailed powerpoint from a sematech symposium on these things. Perhaps an expert reader can contribute here....
Sorry Doug, I was your first Unknown. Jeff Mackey, PhD., Rice '00
Thanks, Doug - especially for the well-deserved skepticism especially regarding "press-releases". Having been in industrial research, I've had the misfortune of observing this "business" of spin closely (um, the non-electronic kind, unrelated to any kind of physics, I mean)
Typically corporations like IBM that are at least historically heavy on research but increasingly answerable to bean-counters who don't quite understand how the "research" feeds the company's bottom-line, put out these "press-releases" to excite the press and the great unwashed, on their progress on "research". Their hope, it appears, is that the resultant hype by the press will somehow lift the stock-price of the company and keep the bean-counters off the researchers' backs, at least temporarily. IBM is most particularly deft at this - I think you have also commented on this with appropriate skepticism in the past (on their Vanadium oxide work, if my memory serves me right).
Sadly, even many Universities have joined this band-wagon somewhat lately (Stanford comes to mind), touting "revolutionary advances" that "may be" borne out of some research - while glossing over the details, nuances and challenges.
Its just sad.
Doug,
Gate "width" of 60nm for 14nm-node transistors refers to the "wrap-around" length of the gate, i.e. is roughly equal to twice the fin height. The actual channel length is of the order of 20nm. The latter used to be referred to as the "node" length, but, as you mention, node length has now become completely meaningless and disconnected from any real transistor dimension.
I agree with the the two Anons. After years of exposure, I've come to despise the technical marketing aspects, and take them as about 50% true. One measurement device I worked with touted "more than a million data points per wafer!", which actually meant that the process over samples by a factor of 1000 or more. The node number used to have a real meaning: it was the smallest pitch that could be printed consistently in a line-space pattern. Now it's just some kind of nominal designation. For the readers who may not be clear on the point, pitch is what really matters. It's possible to print an isolated line line that is very narrow. The challenge comes in printing that line as part of an array of such lines.
Lithographic resolution is governed by R = k1 * lamba / NA. lambda is the laser wavelength, NA is numerical aperture, and k1 is a constant. The equation is often flipped to the form k1 = R * NA/lambda and in this case, k1 becomes something of a figure of merit. You plug in the resolution you would need and the available NA and lambda to give a measure of the "difficulty" of the process. If k1 is less than, say, 0.3, you know you need to pull out the bag of tricks to get a stable manufacturable process. If k1 is smaller than, say 0.25, the process may be impossible to achieve without using near-field imaging as beautifully demonstrated by Fang, et al., in Fig 8.32 of Doug's book.
Jeff M.
Post a Comment